Each Dollar is 1000 Credits
Each Dataset is 5 credits, regardless of size. Pay only for what you use!
And your Credits Never Expire
The WorldData.AI Public API is compatible with any programming language that can consume REST APIs, however, to ensure developers can use the service with ease, we have created language-specific client libraries. Please refer to the available languages in the navigation sidebar under 'Client Libraries' section to see the instruction for setting up the environment. There will also be a guide for each language within the individual endpoints sections. We aim to add more language support in the future so please stand by for future announcements.
The following terminologies applies to any library we will develop for any language.
TERMINOLOGIESThe client library for R is currently being developed by our team. Please stand by for future release announcement.
The client library for C# is currently being developed by our team. Please stand by for future release announcement.
1. From pypi:
pip install worlddata
2. From GitHub, Clone our repository:
pip install git+https://github.com/worlddata-ai/python-api.git
Import WorldData library in the Jupyter or Spyder as shown below:

If you are going to make a couple of requests, you can use connection pooling provided by requests. This will save significant time by avoiding renegotiation of TLS (SSL) with the chat server on each call

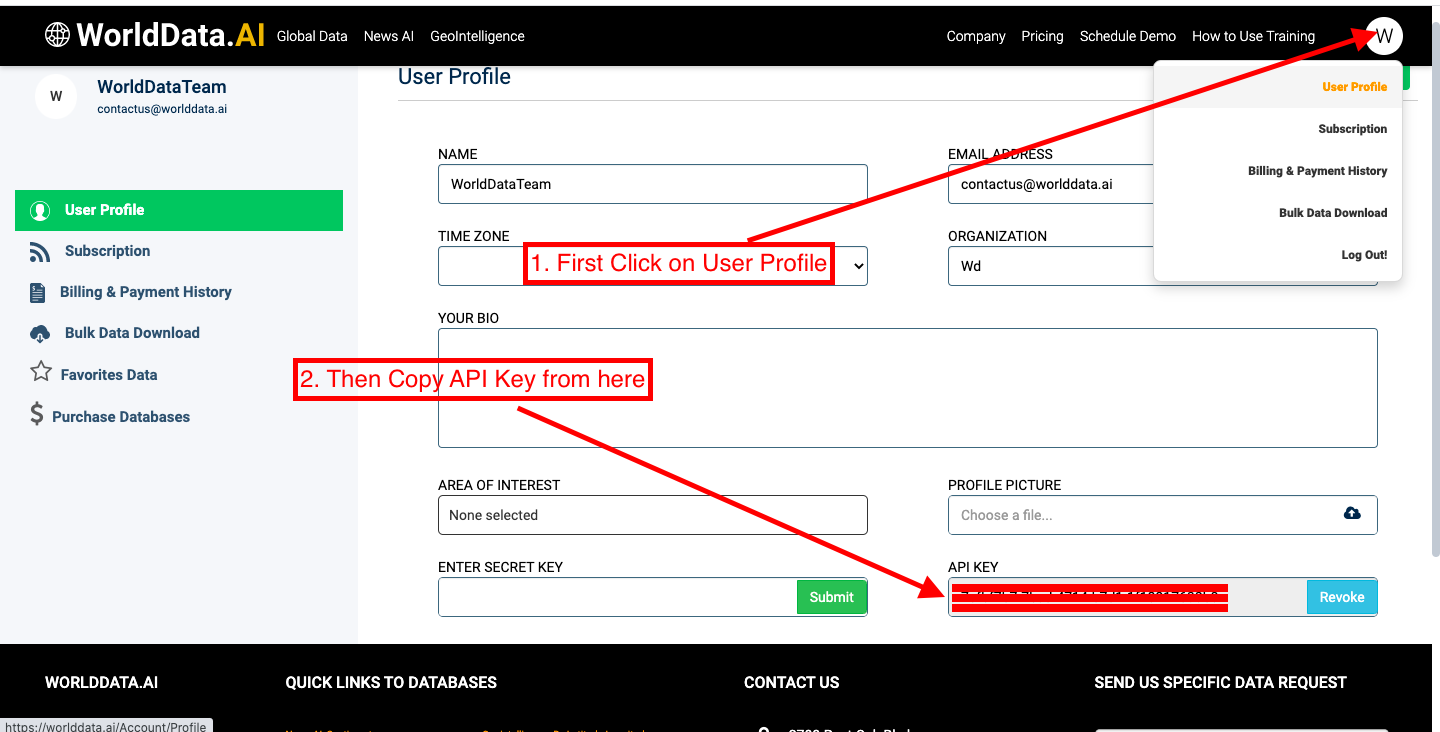
1. Copy API Key as shown in below image
2. Initialize the API key in Python IDE

Use this to Search for the right Database or SSSS
You can input keywords to get a list of relevant databases
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
This API is helpful for getting the right Metadata in a given SSSS.
Select the SSSS you want to explore from the search results of the previous API. Use that set of SSSS as input to the advanced search API. Also Input Search Text which you want to filter
Here is a sample snapshot of output from this api
Each of these results contains trendID which can be used in the next API for getting the time series related to metadata.
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
The Attributes API is helpful to get a list of unique attributes in each and every column of Metadata
Call the api as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
This API is helpful to get Metadata directly by just copying bucket payload from the front end. If you are using this API then you don’t have to use APIs 'Search', 'Advanced Search', 'Advanced Search-Attributes'
1. Copy the bucket payload from the front-end
2. Call the api as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
This API gets you the timeseries data. Output from the 'Advance Search' API will be used as input to this API as it contains trend Ids which will be input along with the set of SSSS
Call the API as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
This API gets you the timeseries data. Output from the 'Advance Search' API will be used as input to this API as it contains trend Ids which will be input along with the bucket Id payload copied from front-end
1. Copy the bucket payload from the front-end
2. Call the API as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
This API is useful for getting the NEWS Sentiment index from the searched keyword on daily as well as monthly frequency. Output value of index ranges from -1 to 1. -1 indicating very negative news, +1 indicating very positive news and 0 means neutral news. The Input to this API is similar to advance search API
Call the API as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
Entity mapping finds out relation between known entities and returns information about those entities. API selects top 25 entities based on frequency of occurrence set as weight. Then it compares each element with each other counting many times they appear together in same news
Call the API as shown below
Here is a sample snapshot of output from this api
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
Here we find out correlation between US employment rate and gross profit of all the listed US companies. Program helps to find out top 30 companies with highest correlation and top 30 companies with lowest correlation.
#!/usr/bin/env python
# coding: utf-8
# # Objective 3. Which companies are highly influenced by overall US employment rate
#adding Lib
from worlddata.worlddata import WorldData
import requests
import json
import pandas as pd
import plotly.express as px
import matplotlib.pyplot as plt
#initializing the API key
worlddata = WorldData(auth_token = 'Your API key')
#Api for text search
worlddata.search(search_text='fiancial statement')
# function to convert Json to CSV from advance search API
def create_ad_df(ad):
column_dict = {'trendId':'','Company Name':''}
df_ad = pd.DataFrame(columns=column_dict.keys())
for x in range(len(ad['results'])):
data_dict = column_dict.copy()
if 'trendId' in ad['results'][x]:
data_dict['trendId'] = ad['results'][x]['trendId']
if 'Company Name' in ad['results'][x]:
data_dict['Company Name'] = ad['results'][x]['Company Name']
if 'Industry Level 1' in ad['results'][x]:
data_dict['Industry Level 1'] = ad['results'][x]['Industry Level 1']
if 'Industry Level 2' in ad['results'][x]:
data_dict['Industry Level 2'] = ad['results'][x]['Industry Level 2']
new_row_ad = pd.Series(data_dict)
df_ad = df_ad.append(new_row_ad, ignore_index=True)
return(df_ad)
#Pagination : Calling the Advance search API in batches of 100
count = 100
limit = 0
df0 = pd.DataFrame()
while 1 == 1:
ad = worlddata.advance_search(search_text = 'financial statement', sector = 'FINANCIAL MARKET',
sub_sector = 'FINANCIAL STATEMENT',
super_region='UNITED STATES', source ='COMPANY SEC FILINGS' , size =100,offset =limit,
all_of_this_words='NEW YORK STOCK EXCHANGE,ANNUAL,GROSS PROFIT')
if ad['count'] > 0:
print(ad['count'],limit)
df1 = create_ad_df(ad)
df0 = pd.concat([df0,df1])
limit = limit + 100
else :
df0 = df0.reset_index(drop=True)
print('out')
break
#Creating list of TrendIds
trend_list = list(df0['trendId'])
#Funtion for creating time series Dataframe
def create_ad_ts(ts) :
column_dict = {'date':'', 'value': '','trend_id':''}
df_ts = pd.DataFrame(columns=column_dict.keys())
for x in range(len(ts['results'])):
data_dict = column_dict.copy()
for y in range(len(ts['results'][x]['time_series'])):
data_dict['date'] = ts['results'][x]['time_series'][y]['date']
data_dict['value'] = ts['results'][x]['time_series'][y]['value']
data_dict['trend_id'] = ts['results'][x]['trend_id']
new_row = pd.Series(data_dict)
df_ts = df_ts.append(new_row, ignore_index=True)
return df_ts
# API call for Time series trends in batches of 100 - Get GROSS PROFIT ANNUAL timeseries data for all 2319 companies
time_series = pd.DataFrame()
l=0
for x in range(int(len(trend_list)/100)+1):
print(l)
ts = worlddata.time_series(sector = 'FINANCIAL MARKET', sub_sector = 'FINANCIAL STATEMENT',
super_region='UNITED STATES', source ='COMPANY SEC FILINGS',
trend_ids = trend_list[l:l+100])
ts1 = create_ad_ts(ts)
time_series = pd.concat([ts1,time_series])
l = l+100
time_series = time_series.reset_index(drop=True)
#merging Properties Dataframe with time series trends
financial = pd.merge(left=df0,right =time_series,left_on = 'trendId', right_on = 'trend_id')
# # Financial Data Dataframe
#Steps to clean data according to use
financial = financial[['Company Name','date', 'value']]
financial = financial[financial['date'].str.contains('-12-31')]
financial['year'] = financial['date'].str.replace('-12-31','')
financial.columns = financial.columns.str.replace('value','gross profit')
# # Employment Rate
#Search API
worlddata.search(search_text='employment rate')
#Advance Search API
filters2 = {'Description':['EMPLOYMENT RATE: AGED 15-64: ALL PERSONS FOR THE UNITED STATES'],'Time Level':['ANNUAL']}
worlddata.advance_search(search_text = 'employment rate', sector = 'LABOR STATISTICS', sub_sector = 'EMPLOYMENT POPULATION RATIO',super_region='UNITED STATES', source ='FEDERAL RESERVE ECONOMIC DATA-FRED' , size =100,offset = 0,filters = filters2)
#Time Series API
ts = worlddata.time_series(sector = 'LABOR STATISTICS', sub_sector = 'EMPLOYMENT POPULATION RATIO', super_region='UNITED STATES',
source ='FEDERAL RESERVE ECONOMIC DATA-FRED',
trend_ids =['NjUzMzk3MjIzNTk3OTA0Mjc1NiQkRlJFRF9ORVdfQVBJX0FubnVhbCQkRlJFRF9ORVdfQVBJX0FubnVhbF9EQVRBVkFMVUU='])
employment_rate = create_ad_ts(ts)
employment_rate
#Cleaning of the Dataframe
employment_rate.columns = employment_rate.columns.str.replace('value','employment_rate')
employment_rate['year'] = employment_rate['date'].str.replace('-01-01','')
# # Merging financial and employment rate into one df
merged_df = pd.merge(left = financial, right = employment_rate,left_on='year',right_on = 'year')
merged_df = merged_df[['Company Name', 'gross profit', 'year','employment_rate']]
merged_df
# # Correlation
fig = px.bar(merged_df[merged_df['Company Name'] == 'DOVER MOTORSPORTS INC.'], x="year", y="gross profit")
fig.show()
fig1 = px.bar(merged_df[merged_df['Company Name'] == 'DOVER MOTORSPORTS INC.'], x="year", y="employment_rate")
fig1.show()
#Dataframe with Correlation Values
column_dict = {}
correlation_df = pd.DataFrame(columns=column_dict.keys())
for x in merged_df['Company Name'].unique():
if len(merged_df[merged_df['Company Name'] == x])>20:
data_dict = column_dict.copy()
data_dict['Company Name'] = x
data_dict['Correlation_value'] = merged_df[merged_df['Company Name'] == x].corr().values[0][1]
new_row_ad = pd.Series(data_dict)
correlation_df = correlation_df.append(new_row_ad,ignore_index = True)
correlation_df
# # Top 30 Companies with max correlation coff
correlation_df.sort_values(by = 'Correlation_value', ascending=False,ignore_index=True)[0:30]
# # Top 30 Companies with min correlation coff
correlation_df.sort_values(by = 'Correlation_value', ascending=True,ignore_index=True)[0:30]
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
Here we find out the impact of the Composite NEWS sentiment Index of leading private banks in India (HDFC Bank, ICICI Bank, Kotak Mahindra Bank) on the bank NIFTY indices listed on National stock exchange. We find that % change in Index value of NIFTY PRIVATE BANK and NIFTY BANK is significantly explained by composite NEWS sentiment Index. Whereas, % change in Index value of NIFTY PSU Bank not explained by composite sentiment as the P value is insignificant at 95% interval.
#!/usr/bin/env python
# coding: utf-8
# Import libraries
from worlddata.worlddata import WorldData
from datetime import datetime
import requests
import json
import pandas as pd
import plotly.express as px
import matplotlib.pyplot as plt
from datetime import datetime
from scipy import stats
#initializing the API key
worlddata = WorldData(auth_token = 'Your API Key')
# # Basic funtions for JSON to CSV
#Creating Dataframe for Advance search API responce
def create_ad_df(ad):
column_dict = {'trendId':'','Stock Name':''}
df_ad = pd.DataFrame(columns=column_dict.keys())
for x in range(len(ad['results'])):
data_dict = column_dict.copy()
if 'trendId' in ad['results'][x]:
data_dict['trendId'] = ad['results'][x]['trendId']
if 'Stock Name' in ad['results'][x]:
data_dict['Stock Name'] = ad['results'][x]['Stock Name']
new_row_ad = pd.Series(data_dict)
df_ad = df_ad.append(new_row_ad, ignore_index=True)
return(df_ad)
#Creating dataframe for timeseries api responce
def create_ad_ts(ts) :
column_dict = {'date':'', 'value': '','trend_id':''}
df_ts = pd.DataFrame(columns=column_dict.keys())
for x in range(len(ts['results'])):
data_dict = column_dict.copy()
for y in range(len(ts['results'][x]['time_series'])):
data_dict['date'] = ts['results'][x]['time_series'][y]['date']
data_dict['value'] = ts['results'][x]['time_series'][y]['value']
data_dict['trend_id'] = ts['results'][x]['trend_id']
new_row = pd.Series(data_dict)
df_ts = df_ts.append(new_row, ignore_index=True)
return df_ts
#Creating Dataframe of news sentiment api responce
def create_n_ts(ts) :
column_dict = {'key':'', 'sentiment':''}
df_ts = pd.DataFrame(columns=column_dict.keys())
for x in range(len(ts['results'])):
data_dict = column_dict.copy()
data_dict['key'] = ts['results'][x]['key']
data_dict['sentiment'] = ts['results'][x]['value']
new_row = pd.Series(data_dict)
df_ts = df_ts.append(new_row, ignore_index=True)
return df_ts
# # Financial Data
#Advance search API calling Financial Data
ad = worlddata.advance_search(search_text = '', sector = 'FINANCIAL MARKET', sub_sector = 'GLOBAL STOCK EXCHANGE DATA',super_region='GLOBAL DATA', source ='WORLDDATA.AI' ,size =100,offset=0,all_of_this_words='NIFTY BANK',exact_phrase_search='CHANGE(%)')
#Converting json to dataframe
advance_df = create_ad_df(ad)
#Creating list for input in timeseries api
trends = list(advance_df['trendId'])
#Calling timeseries api in batches of 100
init_time = datetime.now()
time_series = pd.DataFrame()
l=0
for x in range(int(len(trends)/100)+1):
print(l)
ts = worlddata.time_series(sector = 'FINANCIAL MARKET', sub_sector = 'GLOBAL STOCK EXCHANGE DATA',super_region='GLOBAL DATA', source ='WORLDDATA.AI' ,trend_ids = trends[l:l+100])
print('Step_1')
ts1 = create_ad_ts(ts)
#print('Step_2')
time_series = pd.concat([ts1,time_series])
# print('Step_3')
l = l+100
print('Step_final')
fin_time = datetime.now()
print(fin_time)
print("Execution time : ", (fin_time-init_time))
#Merging Properties and Time series Dataframes
stock_index =pd.merge(left=time_series,right =advance_df,left_on='trend_id',right_on='trendId')
stock_index = stock_index[['Stock Name','date','value']]
stock_index
# # NEWS AI
# Advance Search API for News sentiment
worlddata.advance_search(search_text = '', sector = 'NEWS AI, SENTIMENTS', sub_sector = 'FINANCIAL NEWS',super_region='GLOBAL DATA', source ='WORLDDATA.AI' ,
size =100,offset=0,any_of_this_words='HDFC Bank,ICICI Bank, Kotak Mahindra Bank')
# API to get sentiment index
news_sentiment = worlddata.news_sentiment(type ='DAY', search_text = '', sector = 'NEWS AI, SENTIMENTS',sub_sector = 'FINANCIAL NEWS', super_region='GLOBAL DATA', source ='WORLDDATA.AI' ,any_of_this_words='HDFC Bank, ICICI Bank, Kotak Mahindra Bank')
news_sentiment
#Calling json to df funtion and cleaning the df
news_sentiment_df = create_n_ts(news_sentiment)
news_sentiment_df['key'] = news_sentiment_df['key'].str.replace('T00:00:00.000Z','')
news_sentiment_df
# # Combining Both the Dataframes for Regression
#Merging Stock Index and News Sentiments Dataframes, and applying filters
combined = pd.merge(left = stock_index, right = news_sentiment_df,left_on='date',right_on = 'key',how='inner')
combined = combined[['Stock Name', 'date', 'value','sentiment']]
combined = combined[(combined['date'].str.contains('2021')) | (combined['date'].str.contains('2020'))]
combined
#Graphs for NIFTY BANKS
fig = px.line(combined[combined['Stock Name'] == 'NIFTY BANK'], x="date", y="value")
fig.show()
fig2 = px.bar(combined[combined['Stock Name'] == 'NIFTY BANK'], x="date", y="sentiment")
fig2.show()
# Calling Regression Funtion
column_dict = {}
regresion = pd.DataFrame(columns=column_dict.keys())
for x in combined['Stock Name'].unique():
data_dict = column_dict.copy()
data_dict['Stock Name'] = x
slope, intercept, r, p, std_err = stats.linregress(combined[combined['Stock Name'] == x]['value'],combined[combined['Stock Name'] == x ]['sentiment'] )
data_dict['Correlation_value'] = r
data_dict['P_value'] = p
data_dict['Intercept'] = intercept
data_dict['Slope'] = slope
data_dict['Standard Error'] = std_err
new_row_ad = pd.Series(data_dict)
regresion = regresion.append(new_row_ad,ignore_index = True)
# Regression Results
regresion = regresion[['Stock Name','Correlation_value', 'Intercept','Slope', 'P_value','Standard Error']]
regresion
The R client library is under development, please wait for release announcement and check back soon
The C# SDK\Client-library is under development, please wait for release announcement and check back soon
Don’t have an account? Sign Up now. It takes only 2 minutes.
Sign Up with social media
Please enter the details below!
Please enter the details below and we will contact you!

Out of credits?
Gain credits by choosing any below options




Confirm to remove...
